Buzzwords like Artificial Intelligence, Machine Learning, and Data Analysis are used frequently in the modern business world. Every company wants its product to sell better than its competitors’ and every business wants to appeal to as large of an audience as they possibly can. But how can founders and leaders make sure that their business model is working? While Artificial Intelligence can certainly help to improve business processes and Chatbots can accelerate customer experience, there is more that a company can do proactively to measure and monitor the results of their hard work.
In a data-driven environment, either a dedicated team or one specific person per team is oftentimes responsible for collecting and analyzing data, drawing conclusions, and recommending changes to Senior Management. These people can have different titles, including but not limited to: Data Scientist, Data Analyst, and Data Engineer.
Data
Data Scientist
It is generally difficult to accurately define Data Science. Simply put, Data Science is used to tackle a large amount of data, cleansing, preparing, and analyzing it. A Data Scientist will gather data from various sources and apply different tactics and use multiple tools to extract crucial information (ex. Machine Learning, predictive analytics, sentiment analysis, algorithms, data modeling, etc.). They understand data not only from a technical but also from a business viewpoint, which thus provides accurate predictions/forecasts/recommendations and insights that are used to power critical business decisions.
A Data Scientist has strong skills in coding (Python, SAS, R, SQL), is able to work with unstructured data (video, text, social media, etc.), is typically highly analytical and has knowledge of Machine Learning.
In a lot of cases, even if you don’t start out as a Data Scientist (perhaps a Data Analyst or Engineer), you can get there eventually. Some candidates claim they want to start out with Engineering/Analysis and then become a Data Scientist at a later stage.
That makes a Data Scientist a valuable member of any company and is therefore currently in strong demand in Japan. Specifically, companies that operate in the web services industry sometimes have multiple headcounts or multiple teams that need a Data Scientist. One other area that sees a rising number in Data Scientist job openings is FinTech!
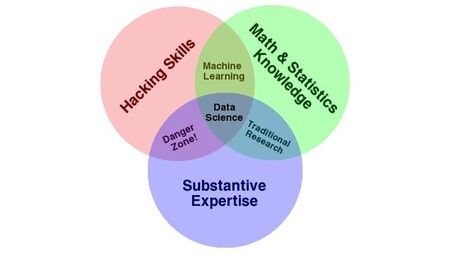
Source: North Eastern University
Data Analyst
A Data Analyst, on the other hand, works way more statistical and visual. They utilize data to solve problems and answer important business questions (ex. why are sales numbers dropping in a certain quarter, why did a certain marketing campaign fare better in a certain region). These people can specialize in a certain domain as well and be a:
- Sales Analyst,
- Financial Analyst,
- Marketing Analyst,
- Customer Success Analyst,
- Etc.
The best Data Analysts will be able to utilize their technical expertise as well as communicate and visualize their findings effectively to a non-technical audience.
They need strong skills in mathematical statistics, coding (mainly Python, R, Excel, SAS), as well as database management.
A Data Analyst (as mentioned before) can specialize in various industries and is therefore fairly flexible in his career options. If the Data Analyst in question does not want to deal with just in-house data, they have the very lucrative option of joining a Data Analytics company, which will more or less outsource their own analysts to their clients and have them analyze the data (potentially onsite), before calling them back and/or assigning them a new client. That makes the job very colorful!
Data Scientist vs. Data Analyst
Generally speaking, a Data Scientist is responsible for predicting future trends, making forecasts and recommendations, while a Data Analyst’s main task is to extract insights from data and communicate/visualize what they found effectively.
“A Data Scientist creates questions while a Data Analyst finds answers to existing questions.”
Data Engineer
Data Engineers, in turn, are responsible for collecting relevant data and making it accessible to the Data Science teams. Sometimes they are referred to as Data Architects. They might be tasked with designing the big data infrastructure in the first place and prepare the data so the Scientists/Analysts can effectively analyze the data.
They need to be skillful in logical thinking, management and organizational skills, coding (Java, Scala, C++ or Python), and be able to work with cross-functional teams.
The title “Data Engineers” per se aren’t sought for so often but you’ll see their job descriptions in the financial industry or insurance industry a lot. Since Data Engineers are experts at working with raw data as well as running data infrastructure, they are often requested in places with huge data influx and/or dynamic data. Legacy systems in a company always pose a unique challenge to a Data Engineer as well.
Sometimes, a Data Engineer can come from a more backend focused role and grow into the role, depending on their company needs. The career path of a Data Engineer is therefore partly shared with Data Analysts and Scientists, but has a specific infrastructure characteristic that differs from the other two.
To sum it up:

Source: European Leadership University
Machine Learning and Machine Learning Engineers
Now, with all the modern technology that we have, do we even need someone to collect, analyze and visualize data? The ability of machines to predict outcomes based on data without being programmed to do so can be called Machine Learning (generally defined as the computer systems’ ability to learn from the environment and autonomously improve itself from experience without explicit coding). Machine Learning is thus about creating algorithms that enable the machine to receive and use data to analyze patterns, make predictions and give recommendations on their own. It cannot be implemented without data.
The role of a Machine Learning Engineer can generally be very versatile. Sometimes they take on specific Data Analyst responsibilities, sometimes they are more specialized in Artificial Intelligence and the development of algorithms instead. Whenever a company needs one of their programs or machines to become smart, they want to hire a Machine Learning Engineer. Sometimes the company in question is not sure yet which direction the program should take, which is where a Machine Learning Engineer might be expected to have a diversified skillset (e.g. Computer Vision, Natural Language Processing and Data experience).
Most Machine Learning Engineers will deal with Python, Tensorflow, or Keras on a daily basis. While there is a possibility of one Data Analyst/Scientist/Engineer per company or team, some companies establish teams made of a number of Machine Learning Engineers to tackle problems in a team. For example, some companies might operate on a “pair programming” basis, which means that all code that is to be written, will be written by at least two people that writes the code together. That means Machine Learning Engineers are often required to work with other people with similar skillsets and backgrounds to achieve the same goal, while Data experts often deal with people outside of their area of expertise and are expected to teach/explain/simplify their findings to an inexperienced audience.
In that sense, none of these roles will really interfere in the others’ expertise. All roles have their specialization and need within a company and fulfill different requirements. In most big companies, there will be a need for multiple people with the same job description. In a best case scenario, all of these can peacefully and effectively work as a team to help their company streamline processes and make the best use of the material they have. They will make sense of the data they have, propose an attack plan to solve any issues and make sure any solution will be implemented properly. After all, a modern world requires modern solutions to tackle modern problems.
The three basic models of Machine Learning are supervised, unsupervised, and reinforcement learning.
Supervised Learning
In supervised learning, pre-existing labeled data helps machines recognize characteristics to predict or analyze future data. For example, you classify a few pictures labeled ‘cats’ and a few pictures labeled ‘dogs’ and the machine will classify the remaining pictures based on the pictures provided.
A good example can be handwriting recognition. When the computer is shown a number of handwritten digits (as images) along with the correct labels for each digit. It learns the patterns that relate images to their respective labels. The important thing to note here is that it is absolutely crucial to have access to a dataset of correct input-output pairs (in this case, images and their respective labels). In the handwriting example, that means we need a human to classify the images in the training set prior to the machine’s data prediction.
Supervised learning has two subgroups.
|
Regression |
Classification |
|
|
Unsupervised Learning
In unsupervised learning, we put unlabeled data into the machine and let it understand, classify, and label everything on its own. That means compared to the data with the ‘correct answers’, we now have a set of data without a ‘correct answer’, potentially because we don’t know the answer, or there is simply no ‘correct’ answer to begin with. One large subclass of this method is called Clustering.
Clustering is the action of grouping certain observations in a way that members of a common group are similar to each other and different from members of other groups. This can be exceptionally useful in marketing for example, in case we want to identify segments of customers with similar preferences/buying habits. The difficulty in clustering is that it is difficult (and often impossible) to know how many clusters should exist or how they should look in the first place.
An interesting class of unsupervised tasks is generative modeling. These models imitate the process that generates the training data. A good model will be able to generate new data that resembles the training data in some sense. Since the process that generates the data is not directly observable (only the data itself) it is part of unsupervised learning. This leads to startling and sometimes horrifying advances in image generation (think fake images, “Deep Fake”), but can also be quite useful to brush up your vacation pictures (ex. removing other people from your photos as shown in one of the images below).
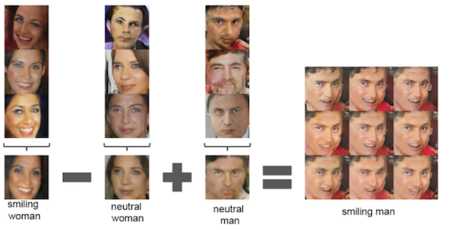

Source: Cornell University

Source: Andrea Janda, Flickr
Reinforcement Learning
Reinforcement learning simply refers to an algorithm that interacts with the environment by completing an action and analyzing errors or rewards (i.e. find the best ways to earn the biggest rewards, like winning a game, solving a puzzle, earning money, etc.). This method is very similar to how humans and animals learn: the machine tries a bunch of different things and gets a reward when it does something well. This is useful when the solution space is enormous (and not just one ‘correct’ solution). One of the first successful stories for this model was when a small team trained a reinforcement learning model to play Atari video games using only the pixel output from the game as input. Eventually, the model outperformed human players, pushing Google to acquire the company shortly after.
So, instead of using millions and billions of examples of human players to be used as input (supervised learning), this method works by giving the machine a reward based on how well it plays (where a score works very well as a type of reward, the machine can learn which patterns/behaviors will result in the highest score/biggest reward).
Conclusion
Data is necessary to draw insights, predict outcomes, and generate new data. However, accuracy is crucial for each result, whether it’s generated by a human operator or a machine. In a business a Data Engineer might collect and prepare the data, a Data Analyst will work with the available data and answer business questions (as well as visualize data and results), and a Data Scientist will be able to ask more questions and predict future outcomes.
Without a human operator, a machine has different ways of working with data (labeled or unlabeled). Depending on how skillful your Machine Learning Engineer is, the models can be more or less accurate and will be able to improve recognition, forecast, and recommendation with more data that it is being fed.
At RGF Professional we make sure to speak to every candidate and client in detail before matching them with each other. Depending on the candidates’ technical skills and requirements, they will make an excellent match to a variety of companies with a multitude of different ambitions. Even such nuances as differences between Data Scientists and Analysts (which are often treated the same by businesses) come into work during our careful screening and interviewing process.
Make sure to check out our redesigned website today, register your profile and be the first to learn about exciting opportunities in Data or Machine Learning!

Working at a global company has many advantages, not only for those who want to work globally and those who want to make use of their language skills, but also for people who strive to Unleash their Potential seek their own potential and have a healthy work-life balance.
RGF Professional Recruitment Japan supports the recruitment hiring activities of many of the top domestic and foreign capital companies in Japan. Various excellent companies including foreign and Japanese global companies located in Japan. Therefore, as a result, we can introduce the best career options for each person.to suite all types of career profile.
If you want to work in a global environment or globally, want to work in a place where you can perform more, or want toto a higher level and expand your career options in the future, please contact us. Our experienced consultants will do their best to support your career growth.